为了在项目中快捷方便的代码生成,将mybatis-plus-generator封装为了一个maven的插件
mybatis-plus-generator-maven-plugin,在要使用的项目pom文件引入该插件,执行mvn命令,即可直接生成代码到项目中,生成基于mybatis-plus的mapper、service、controller三层结构,包括entity实体类和mapper.xml文件,生成后直接能够满足基本的条件查询和分页查询。下面介绍该插件的使用步骤:
一、下载插件
方式1:CSDN中下载:jar包地址:mybatis-plus-generator-maven-plugin-1.0.0.jar,pom文件地址:pom.xml
方式2:将源代码导入项目工程中,执行mvn intall,源码地址:https://github.com/xiweile/mybatis-plus-generator-maven-plugin
二、插件上传至本地仓库
在下载好的mybatis-plus-generator-maven-plugin-1.0.0.jar和pom.xml文件目录下打开命令行工具,执行下面命令-DpomFile为pom.xml所在目录,-Dfile是jar所在位置,-Dpackaging固定为 maven-plugin,其他参数此处不介绍。1
mvn install:install-file -DpomFile=pom.xml -Dfile=mybatis-plus-generator-maven-plugin-1.0.0.jar -DgroupId=com.weiller -DartifactId=mybatis-plus-generator-maven-plugin -Dversion=1.0.0 -Dpackaging=maven-plugin
三、在pom中引入插件
在要使用插件的工程pom文件中引入该插件,如下案例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<!-- mybatis-plus generator 自动生成代码插件 -->
<plugin>
<groupId>com.weiller</groupId>
<artifactId>mybatis-plus-generator-maven-plugin</artifactId>
<version>1.0.0</version>
<configuration>
<configurationFile>${basedir}/src/main/resources/generator/mp-code-generator-config.yaml</configurationFile>
</configuration>
</plugin>
<!-- mybatis-plus generator 自动生成代码插件 -->
</plugins>
</build>
注意configurationFile参数为 下一步中配置文件generator-config的位置,该文件类型为yaml。
四、填写配置文件
配置完整案例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44globalConfig:
author: weiller
open: false
idType: INPUT
dateType: ONLY_DATE
enableCache: false
activeRecord: false
baseResultMap: true
baseColumnList: true
swagger2: false
fileOverride: true
dataSourceConfig:
url: jdbc:mysql://localhost:3306/demo?useUnicode=true&useSSL=false&characterEncoding=utf8
driverName: com.mysql.jdbc.Driver
username: root
password: xiweile
packageConfig:
parent: com.weiller
moduleName: rest
entity: model
service: service
serviceImpl: service.impl
mapper: dao
xml: mapper
controller: controller
pathInfo:
entity_path: src\main\java\com\weiller\rest\model
service_path: src\main\java\com\weiller\rest\service
service_impl_path: src\main\java\com\weiller\rest\service\impl
mapper_path: src\main\java\com\weiller\rest\dao
xml_path: src\main\resources\com\weiller\rest\mapper
controller_path: src\main\java\com\weiller\rest\controller
strategyConfig:
naming: underline_to_camel
columnNaming: underline_to_camel
entityLombokModel: true
superMapperClass: com.baomidou.mybatisplus.core.mapper.BaseMapper
superServiceClass: com.baomidou.mybatisplus.extension.service.IService
superServiceImplClass: com.baomidou.mybatisplus.extension.service.impl.ServiceImpl
controllerMappingHyphenStyle: true
restControllerStyle: true
tablePrefix:
include:
- t_user
配置项参数解释:https://mp.baomidou.com/config/generator-config.html#基本配置
五、运行maven命令
在命令工具中,进入到要生成项目的根目录(即pom.xml目录),执行以下命令1
mvn mybatis-plus-generator:generator
如果是使用InterlliJ IDEA工具,使用更加方便,步骤如下图:
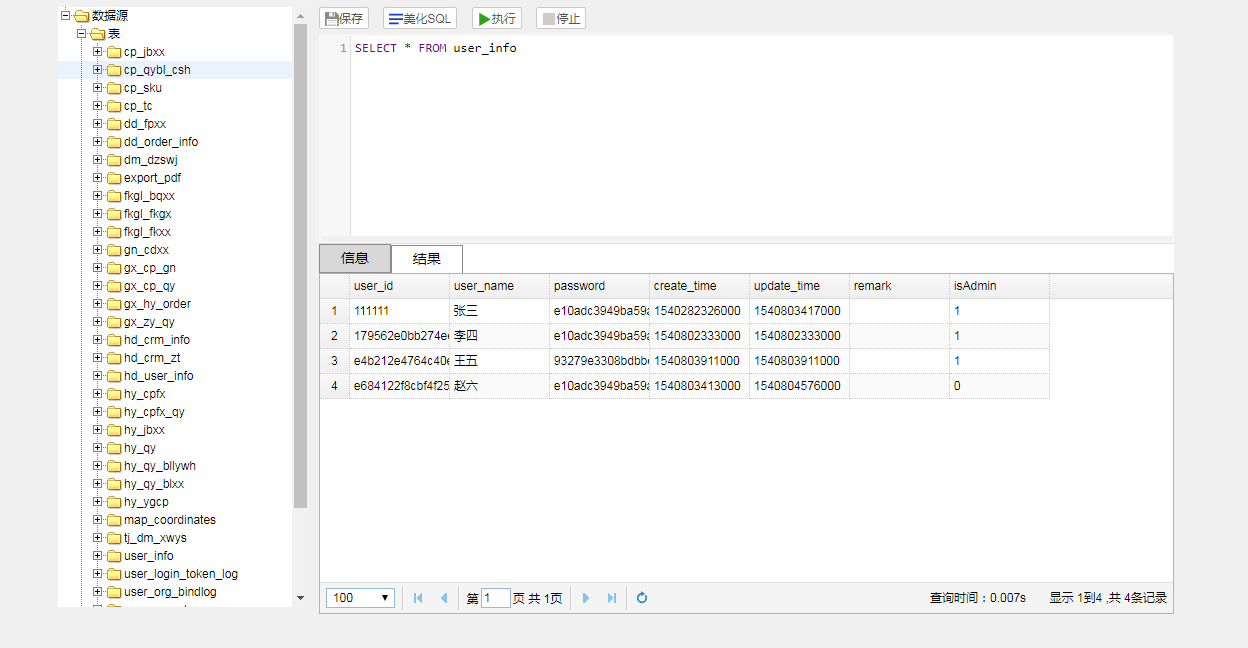
生成结果如下: